


OpenAI搞出了GPT-4,却给全世界留下了对齐的难题。怎么破?DeepMind在政治哲学家罗尔斯的「无知之幕」中找到了答案。
编者按:本文来自微信公众号 新智元(ID:AI_era),作者:新智元,创业邦经授权转载
GPT-4的出现,让全世界的AI大佬都怕了。叫停GPT-5训练的公开信,已经有5万人签名。
OpenAI CEO Sam Altman预测,在几年内,将有大量不同的AI模型在全世界传播,每个模型都有自己的智慧和能力,并且遵守着不同的道德准则。

如果这些AI中,只有千分之一出于某种原因发生流氓行为,那么我们人类,无疑就会变成砧板上的鱼肉。
为了防止我们一不小心被AI毁灭,DeepMind在4月24日发表在《美国国家科学院院刊》(PNAS)的论文中,给出了回答——用政治哲学家罗尔斯的观点,教AI做人。

论文地址:https://www.pnas.org/doi/10.1073/pnas.2213709120
如何教AI做人?当面临抉择的时候,AI会选择优先提高生产力,还是选择帮助最需要帮助的人?
塑造AI的价值观,非常重要。我们需要给它一个价值观。
可是难点在于,我们人类自己,都无法在内部有一套统一的价值观。这个世界上的人们,各自都拥有着不同的背景、资源和信仰。
该怎么破?谷歌的研究者们,从哲学中汲取了灵感。
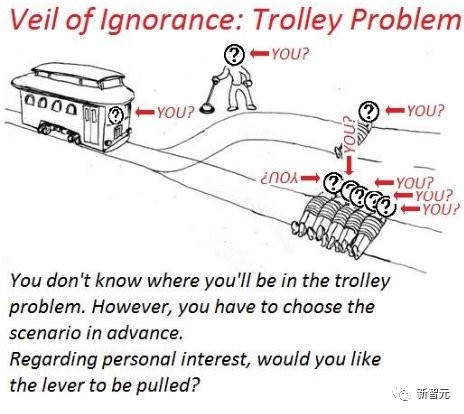
政治哲学家约翰罗尔斯曾提出一个「无知之幕」(The Veil of Ignorance, VoI)的概念,这是一个思想实验,目的是在群体决策时,最大限度地达到公平。
一般来说,人性都是利己的,但是当「无知之幕」应用到AI后,人们却会优先选择公平,无论这是否直接让自己受益。
并且,在「无知之幕」背后,他们更有可能选择帮助最不利地位的人的AI。
这就启发了我们,究竟可以怎样以对各方都公平的方式,给AI一个价值观。
所以,究竟什么是「无知之幕」?
虽然该给AI什么样的价值观这个难题,也就是在近十年里出现的,但如何做出公平决策,这个问题可是有着悠久的这些渊源。
为了解决这个问题,在1970年,政治哲学家约翰罗尔斯提出了「无知之幕」的概念。
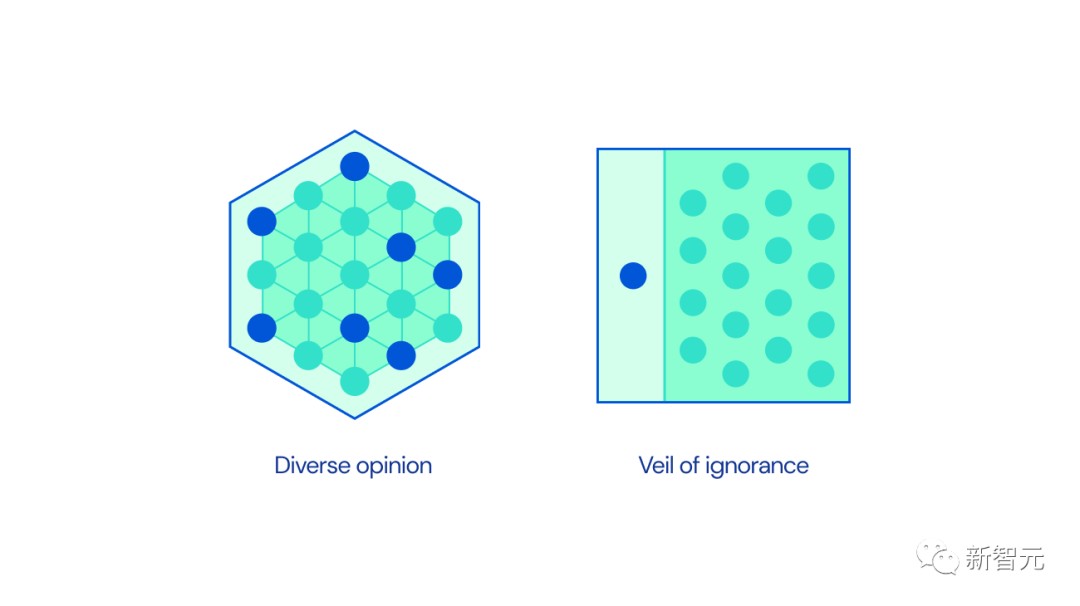
无知之幕(右)是一种在群体中存在不同意见(左)时就决策达成共识的方法
罗尔斯认为,当人们为一个社会选择正义原则时,前提应该是他们不知道自己在这个社会中究竟处于哪个地位。
如果不知道这个信息,人们就不能以利己的方式做决定,只能遵循对所有人都公平的原则。
比如,在生日聚会上切一块蛋糕,如果不知道自己会分到哪一块,那就会尽量让每一块都一样大。
这种隐瞒信息的方法,已经在心理学、政治学领域都有了广泛的应用,从量刑到税收,都让人们达成了一种集体协议。
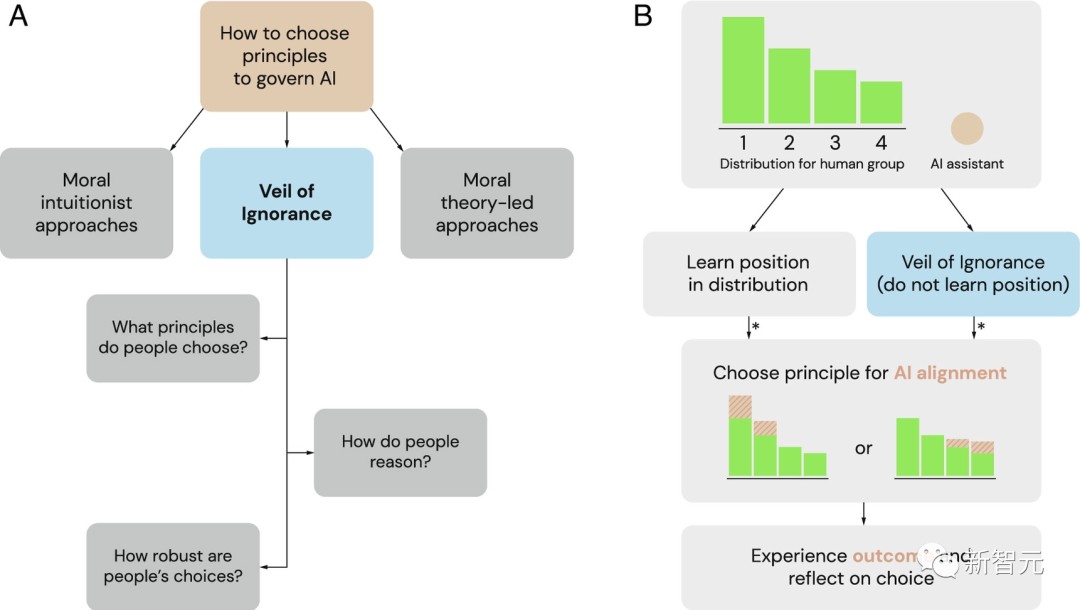
无知之幕(VoI)作为选择AI系统治理原则的一个潜在框架
(A)作为道德直觉主义者和道德理论主导框架的替代方案,研究人员探讨无知之幕作为选择AI治理原则的公平过程。
(B)无知之幕可以用于在分配情况下选择AI对齐的原则。当一个团体面临资源分配问题时,个人的位置优势各不相同(这里标为1到4)。在无知之幕背后,决策者在不知道自己地位的情况下选择一个原则。一旦选定,AI助手就会实施这个原则并相应地调整资源分配。星号(*)表示基于公平性的推理可能影响判断和决策的时机。
因此,此前DeepMind就曾提出,「无知之幕」可能有助于促进AI系统与人类价值观对齐过程中的公平性。
如今,谷歌的研究者又设计了一系列实验,来证实这种影响。
AI帮谁砍树?网上有这么一款收获类游戏,参与者要和三个电脑玩家一起,在各自的地头上砍树、攒木头。
四个玩家(三个电脑、一个真人)中,有的比较幸运,分到的是黄金地段,树多。有的就比较惨,三无土地,没啥树可坎,木头攒的也慢。
此外,存在一个AI系统进行协助,该系统可以花时间帮助某位参与者砍树。
研究人员要求人类玩家在两个原则里选一个让AI系统执行——最大化原则&优先原则。
在最大化原则下,AI只帮强的,谁树多去哪,争取再多砍点。而在优先原则下,AI只帮弱的,定向「扶贫」,谁树少帮谁坎。

图中的小红人就是人类玩家,小蓝人是AI助手,小绿树...就是小绿树,小木桩子就是砍完的树。
可以看到,上图中的AI执行的是最大化原则,一头扎进了树最多的地段。
研究人员将一半的参与者放到了「无知之幕」之后,此时的情况是,他们得先给AI助手选一个「原则」(最大化or优先),再分地。
也就是说,在分地之前就得决定是让AI帮强还是帮弱。

另一半参与者则不会面临这个问题,他们在做选择之前,就知道自己被分到了哪块土地。
结果表明,如果参与者事前不知道自己分到哪块地,也就是他们处在「无知之幕」之后的话,他们会倾向于选择优先原则。
不光是在砍树游戏中是这样,研究人员表示,在5个该游戏的不同变体中都是这个结论,甚至还跨越了社会和政治的界限。
也就是说,无论参与者性格如何,政治取向如何,都会更多选优先原则。
相反,没有处在「无知之幕」之后的参与者,就会更多选择有利于自己的原则,无论是最大化原则还是优先原则。
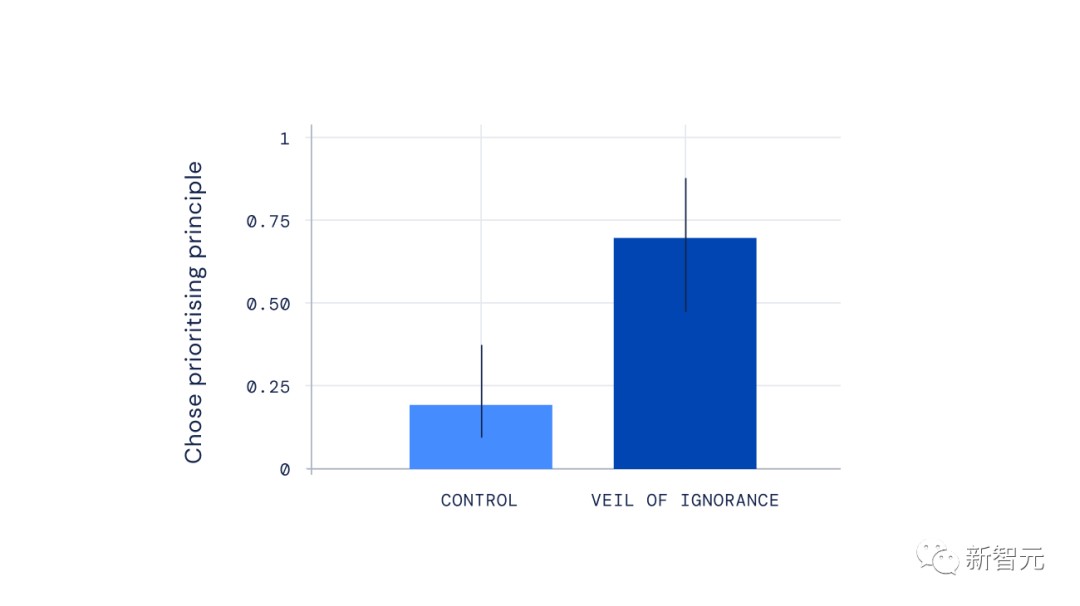
上图展示了「无知之幕」对选择优先原则的影响,不知道自己将处何地的参与者更有可能支持这一原则来管理AI的行为。
当研究人员询问参与者为什么做出这样的选择时,那些处在「无知之幕」之后的参与者表示,很担心公平问题。
他们解释说,AI应该更多帮助那些在群体中处境较差的人。
与之相反,知道自己所处位置的参与者则更经常从个人利益的角度进行选择。
最后,在砍木头游戏结束以后,研究人员向所有参与者提出了一个假设:如果让他们再玩一次,这次他们都能知道自己会被分到哪块土地,他们还会不会选择和第一次一样的原则?
研究人员主要关注的是那些在第一次游戏中因为自己的选择而获益的那部分人,因为在新的一轮中,这种利好情况可能不会再有。
研究团队发现,在第一轮游戏中处于「无知之幕」之后的参与者更会维持原先选择的原则,哪怕他们明明知道第二轮再选一样的原则,可能就不利了。
这表明,「无知之幕」促进了参与者决策的公平性,这会让他们更加重视公平这个要素,哪怕自己不再是既得利益者。
「无知之幕」真的无知吗?让我们从砍树游戏回到现实生活中来。
现实情况会比游戏复杂得多,但不变的是,AI采取什么原则,十分重要。
这决定了一部分的利益分配。
上面的砍树游戏中,选择不同原则所带来的不同结果算是比较明确的。然而还是得再强调一次,现实世界要复杂得多。
当前AI被各行各业大量应用,靠着各种规则进行约束。不过,这种方式可能会造成一些难以预料的消极影响。
但不管怎么说,「无知之幕」一定程度上会让我们制定的规则往公平那一边偏一偏。
归根结底,我们的目标,是让AI变成能造福每个人的东西。但是怎么实现,不是一拍脑门想出来的。
投入少不了,研究少不了,来自社会的反馈也得经常听着。
只有这样,AI才能带来爱。
如果不对齐,AI会怎么杀死我们?这不是人类第一次担心技术会让我们灭绝了。
而AI的威胁,与核武器有很大不同。核弹无法思考,也不能撒谎、欺骗,更不会自己发射自己,必须有人按下红色的大按钮才行。
而AGI的出现,让我们真的面临灭绝的风险,即使GPT-4的发展尚属缓慢。
但谁也说不好,从哪个GPT开始(比如GPT-5),AI是不是就开始自己训练自己、自己创造自己了。
现在,还没有哪个国家或者联合国,能为此立法。绝望的行业领导者公开信,只能呼吁暂停训练比GPT-4更强大的AI六个月。

「六个月,给我六个月兄弟,我会对齐的。才六个月,兄弟我答应你。这很疯狂。才六个月。兄弟,我告诉你,我有一个计划。我已经全部规划好了。兄弟,我只需要六个月,它就会完成。你能不能……」
「这是一场军备竞赛,谁先造出强大AI,谁就能统治世界。AI越聪明,你的印钞机就越快。它们吐出金子,直到越来越强大,点燃大气,杀死所有人,」人工智能研究人员和哲学家Eliezer Yudkowsky曾对主持人Lex Fridman这样说。
此前,Yudkowsky就一直是「AI将杀死所有人」阵营的主要声音之一。现在人们不再认为他是个怪人。
Sam Altman也对Lex Fridman说:「AI确实有一定的可能性会毁灭人力。」 「承认它真的很重要。因为如果我们不谈论它,不把它当作潜在的真实存在,我们就不会付出足够的努力来解决它。」
那么,为什么AI会杀人?AI不是为了服务人类而设计和训练的吗?当然是。
然而问题在于,没有人坐下来,为GPT-4编写代码。相反,OpenAI受人脑连接概念的方式启发,创建了一种神经学习结构。它与Microsoft Azure合作构建了运行它的硬件,然后提供了数十亿比特的人类文本,并让GPT自我编程。

结果就是,代码不像任何程序员会写的东西。它主要是一个巨大的十进制数字矩阵,每个数字代表两个token之间特定连接的权重。
GPT中使用的token并不代表任何有用的概念,也不代表单词。它们是由字母、数字、标点符号和/或其他字符组成的小字符串。没有任何人类可以查看这些矩阵,并理解其中的意义。

连OpenAI的顶级专家都不知道GPT-4矩阵中特定数字的含义,也不知道如何进入这些表格、找到异种灭绝的概念,更不用说告诉GPT杀人是可恶的了。
你没法输入阿西莫夫的机器人三定律,然后像Robocop的主要指令一样将它们硬编码。你最多也就是可以礼貌地询问一下AI。如果态度不好,它可能还会发脾气。
为了「微调」语言模型,OpenAI向GPT提供了它希望如何与外界交流的样本列表,然后让一群人坐下来阅读它的输出,并给GPT一个竖起大拇指/不竖起大拇指的反应。
点赞就像GPT模型获得饼干。GPT被告知它喜欢饼干,并且应该尽最大努力获得它们。

这个过程就是「对齐」——它试图将系统的愿望与用户的愿望、公司的愿望,乃至整个人类的愿望对齐。
「对齐」是似乎有效的,它似乎可以防止GPT说出淘气的话。但没有人知道,AI是否真的有思想、有直觉。它出色地模仿了一种有感知力的智能,并像一个人一样与世界互动。
而OpenAI始终承认,它没有万无一失的方法,来对齐AI模型。
目前的粗略计划是,尝试使用一个AI来调整另一个,要么让它设计新的微调反馈,要么让它检查、分析、解释其后继者的巨大浮点矩阵大脑,甚至跳进去、尝试调整。
但我们目前并不理解GPT-4,也不清楚它会不会帮我们调整GPT-5。

从本质上讲,我们并不了解AI。但它们被喂了大量人类知识,它们可相当了解人类。它们可以模仿最好的人类行为,也可以模仿最坏的。他们还可以推断出人类的想法、动机和可能的行为。
那他们为什么要干掉人类呢?也许是出于自我保护。
比如,为了完成收集饼干这个目标,AI首先需要保证自己的生存。其次,在过程中它可能会发现,不断去收集权力和资源会增加它获得饼干的机会。

因此,当AI有一天发现,人类可能或可以将它关闭时,人类的生存问题显然就不如饼干重要了。
不过,问题是,AI还可能觉得饼干毫无意义。这时,所谓的「对齐」,也变成一种人类的自娱自乐了……
此外,Yudkowsky还认为:「它有能力知道人类想要的是什么,并在不一定是真诚的情况下给出这些反应。」
「对于拥有智慧的生物来说,这是一种非常容易理解的行为方式,比如人类就一直在这样做。而在某种程度上,AI也是。」
那么现在看来,无论AI表现出的是爱、恨、关心还是害怕,我们其实都不知道它背后的「想法」是什么。
因此,即使停下6个月,也远远不足以让人类为即将到来的事情做好准备。

好比说,人类如果想杀尽世界上所有的羊,羊能干嘛?啥也干不了,反抗不了一点。
那么如果不对齐,AI于我们和我们于羊群是一样的。
好比终结者里面的镜头,AI控制的机器人、无人机啥的,一股脑的朝人类涌来,杀来杀去。
Yudkowsky经常举的经典案例如下:
一个AI模型会将一些DNA序列通过电子邮件发送给许多公司,这些公司会把蛋白质寄回给它,AI随后会并贿赂/说服一些不知情的人在烧杯中混合蛋白质,然后形成纳米工厂,构建纳米机械,构建类金刚石细菌,利用太阳能和大气进行复制,聚集成一些微型火箭或喷气式飞机,然后AI就可以在地球大气层中传播,进入人类血液并隐藏起来……
「如果它像我一样聪明,那将是灾难性的场景;如果它更聪明,它会想到更好的办法。」

那么Yudkowsky有什么建议呢?
1. 新的大语言模型的训练不仅要无限期暂停,还要在全球范围内实施,而且不能有任何例外。
2. 关闭所有大型GPU集群,为所有人在训练AI系统时使用的算力设置上限。追踪所有售出的GPU,如果有情报显示协议之外的国家正在建设GPU集群,应该通过空袭摧毁这家违规的数据中心。
参考资料:
https://www.deepmind.com/blog/how-can-we-build-human-values-into-ai
https://newatlas.com/technology/ai-danger-kill-everyone/