



作者:任佳敏来源:i黑马(ID:iheima)
当我们还沉浸于春节的喜悦和忙碌中时,OpenAI悄悄抛出一个超级王炸!
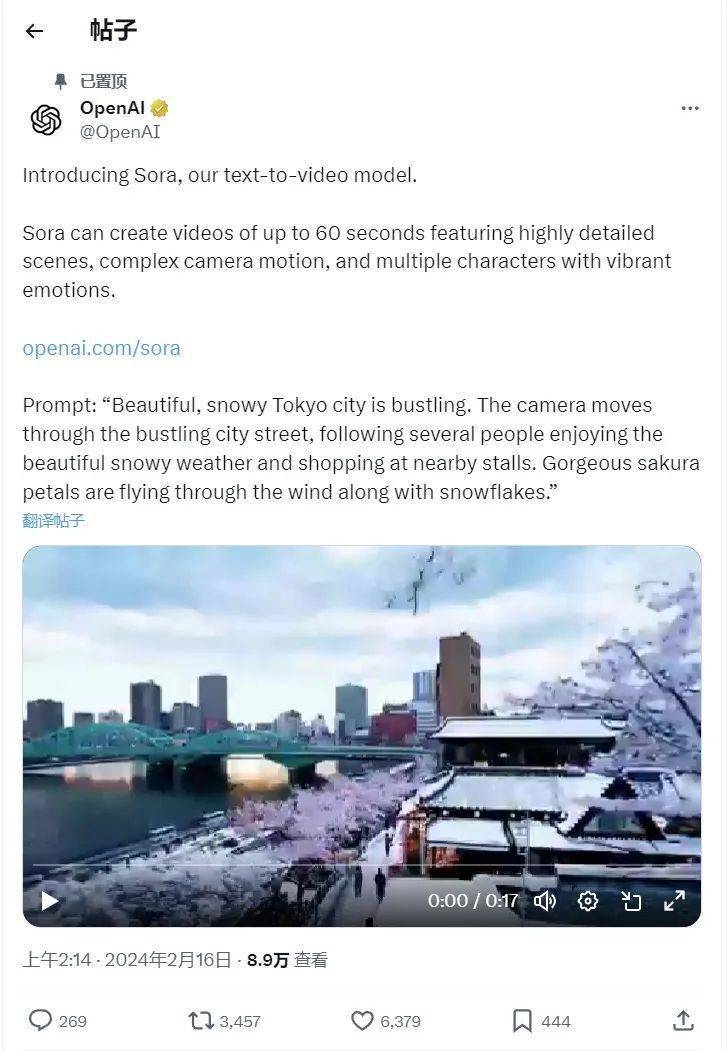
2024年2月16日,OpenAl发布首个文生视频模型——Sora,再次震惊世界!
在震惊之余,不少网友担忧,Sora将彻底颠覆AI视频行业和传统影视广告行业,“掀翻老牌好莱坞人的饭碗”。
这意味着,人类的固有优势领域进一步沦陷,失业人群范围或将继续扩大!

Sora 到底是什么?
通俗点说,Sora能直接用文本生成长达60秒的1080p复杂场景视频,具有良好的连贯性和高质量,直接吊打当前市面上最强的 Pika 和 Runway。
有网友将 Sora 的惊艳之处总结为三点:60秒超级时长、单视频多角度镜头、可读懂世界模型。
1、60秒超级时长。
据了解,行业中大部分AI视频公司,仍在想尽办法解决4秒短视频的连贯性。而Sora一出现就是60秒一镜到底,并能从大中景无缝切换到人物脸部特写。


2、单视频多角度镜头。
在真正的拍摄场景中,实现多镜头场景效果,需要设置多个拍摄机位,以及后期复杂的剪辑流程。目前大部分AI视频,也都是单镜头。
Sora却在60s视频中,实现了多角度镜头丝滑切换,每一个镜头都极为精细,且主体还能保证完美的一致性。

3、可读懂世界模型。
有专业人士表示,世界模型最难的,是收集、清洗数据,但Sora直接做到了。Sora 实现了对现实世界的理解和对世界的模拟两层能力。换句话说,这样生成的视频将更加真实。

有专家认为,OpenAI最终想做的,不只是一个“文生视频”的工具,而是一个通用的“物理世界模拟器”。也就是为真实世界建模。而Sora,只是验证了其可行性,也是一个关键的里程碑。
这些,或许会给AI视频行业、传统影视公司、虚拟拍摄、广告等行业领域,带来致命冲击和深远影响。
比如,很多研发AI视频技术的头部公司,可能在一夜之间前功尽弃,自此被Sora拖在地上使劲摩擦;
比如,未来的电影和短片,或许会由无数个60s短视频组合而成,说不定Sora还会生成60秒以上的视频;
比如,小说作家本身就是导演,可以自编自导自演,而不再需要等待大导演和明星的垂青;
比如,国内百模大战会出现新方向,即将 LLM 和 Diffusion结合起来训练,以实现对现实世界的理解和对世界的模拟两层能力。
比如,Open Al训练将会阅读大量视频,对世界的理解将远超文字学习,AGI的实现或将从10年缩短到1年。
对此,360集团创始人、董事长周鸿祎,也在社交媒体上发表了自己的见解。

除了个人的观察,还理性回应了“Sora 对影视工业的重大打击”、“ Sora将击败抖音、TikTok”等传言,并指明了大模型训练的新方向,非常有参考性价值,这里分享给大家。
以下是正文内容:
周鸿祎年前我在风马牛演讲上分享了大模型十大趋势预测,没想到年还没过完,就验证了好几个,从 Gemini、英伟达的 Chat With RTX到 OpenAl发布 Sora,大家都觉得很炸裂。
朋友问我怎么看 Sora,我谈几个观点,总体来说就是我认为AGI很快会实现,就这几年的事儿了:
第一,科技竞争最终比拼的是让人才密度和深厚积累。
很多人说 Sora的效果吊打 Pika和Runway。这很正常,和创业者团队比,OpenAl 这种有核心技术的公司实力还是非常强劲的。有人认为有了 AI以后创业公司只需要做个体户就行,实际今天再次证明这种想法是非常可笑的。
第二,AI不一定那么快颠覆所有行业,但它能激发更多人的创作力。
今天很多人谈到 Sora 对影视工业的打击,我倒不觉得是这样,因为机器能生产一个好视频,但视频的主题、脚本和分镜头策划、台词的配合,都需要人的创意,至少需要人给提示词。一个视频或者电影是由无数个 60 秒组成的。今天Sora 可能给广告业、电影预告片、短视频行业带来巨大的颠覆,但它不一定那么快击败 TikTok,更可能成为 TikTok的创作工具。
第三,我一直说国内大模型发展水平表面看已经接近 GPT-3.5 了,但实际上跟 4.0 比还有一年半的差距。
而且我相信 OpenAl手里应该还藏着一些秘密武器,无论是 GPT-5,还是机器自我学习自动产生内容,包括 AIGC。奥特曼是个营销大师,知道怎样掌握节奏,他们手里的武器并没有全拿出来。这样看来中国跟美国的 Al 差距可能还在加大。
第四,大语言模型最牛的是,它不是填空机,而是能完整地理解这个世界的知识。
这次很多人从技术上、从产品体验上分析 Sora,强调它能输出 60 秒视频,保持多镜头的一致性,模拟自然世界和物理规律,实际这些都比较表象,最重要的是 Sora 的技术思路完全不一样。因为这之前我们做视频做图用的都是 Diffusion,你可以把视频看成是多个真实图片的组合,它并没有真正掌握这个世界的知识。现在所有的文生图、文生视频都是在 2D 平面上对图形元素进行操作,并没有适用物理定律。
但 Sora 产生的视频里,它能像人一样理解坦克是有巨大冲击力的,坦克能撞毁汽车,而不会出现汽车撞毁坦克这样的情况。
所以我理解,这次 OpenAl 利用它的大语言模型优势,把 LLM 和 Diffusion 结合起来训练,让 Sora 实现了对现实世界的理解和对世界的模拟两层能力,这样产生的视频才是真实的,才能跳出 2D 的范围模拟真实的物理世界。这都是大模型的功劳。
这也代表未来的方向。有强劲的大模型做底子,基于对人类语言的理解,对人类知识和世界模型的了解,再叠加很多其他的技术,就可以创造各个领域的超级工具。比如生物医学,蛋白质和基因研究,包括物理、化学、数学的学科研究上,大模型都会发挥作用。
这次 Sora对物理世界的模拟,至少将会对机器人具身智能和自动驾驶带来巨大的影响。原来的自动驾驶技术过度强调感知层面,而没有工作在认知层面。其实人在驾驶汽车的时候,很多判断是基于对这个世界的理解。比如对方的速度怎么样,能否发生碰撞,碰撞严重性如何,如果没有对世界的理解就很难做出一个真正的无人驾驶。
所以,这次 Sora 只是小试牛刀,它展现的不仅仅是一个视频制作的能力,它展现的是大模型对真实世界有了理解和模拟之后,会带来新的成果和突破。
第五,Open Al训练这个模型应该会阅读大量视频。
大模型加上 Diffusion 技术需要对这个世界进行进一步了解,学习样本就会以视频和摄像头捕捉到的画面为主。一旦人工智能接上摄像头,把所有的电影都看一遍,把YouTube 上和 TikTok 的视频都看一遍,对世界的理解将远远超过文字学习,一幅图胜过千言万语,而视频传递的信息量又远远超过一幅图,这就离AGI真的就不远了,不是10年20年的问题,可能一两年很快就可以实现。