


摘要
在过去的二十年里,高光谱成像已经成为食品质量、安全和作物监测的非破坏性评估的流行。成像提供空间信息,以补充光谱学提供的光谱信息。高光谱图像数据的主要挑战是高维度。每张图像捕获数百个波段。由于波段之间的高多重共线性,将波长数量减少到最佳子集对于速度和鲁棒性至关重要。然而,对于寻找最佳波长子集来预测样品属性的最佳方法,尚未达成共识。一个系统的审查程序被开发和应用于审查已发表的研究高光谱成像和波长选择。综述人群包括从Scopus数据库中检索的所有学科的研究,这些研究提供了来自高光谱图像和应用波长选择的经验结果。我们发现799项研究符合定义的纳入标准,并调查了研究设计、波长选择和机器学习技术的趋势。为了进一步分析,我们考虑了71篇包含空间/纹理特征的英文研究,以了解以前的研究如何将空间特征与波长选择结合起来。本文对每个研究中的波长选择技术进行了排名,以生成每个选择方法的比较性能表。基于这些发现,我们建议未来的研究包括空间特征提取方法,以提高预测性能,并将其与更广泛的波长选择技术进行比较,特别是在提出新方法时。
方法
系统评价对于量化一个研究领域中所有研究的技术和实践的有用性至关重要。本系统综述遵循了David Moher[31]开发的用于系统综述和荟萃分析的首选报告项目(Preferred Reporting Items for systematic Reviews and meta- analysis, PRISMA)框架,调查了应用波长选择技术降低维数的高光谱成像研究以及研究空间特征的研究子集。PRISMA审查包括四个步骤:鉴定、筛选、资格和纳入标准。本节描述在每个步骤中遵循的方法。
研究问题和conceptual framework
本研究通过遵循PRISMA框架对Scopus数据库检索的出版物进行高光谱图像波长选择相关研究。第一阶段的研究问题集中在三个方面:应用领域、研究设计和方法(即特征选择和学习)。我们还为提取空间特征的研究子集纳入了扩展的第二阶段问题。本研究回答了以下研究问题:
标准高光谱研究设计(第2.2节)
- 中移动1 :
-
在高光谱成像研究中获得了多少样品?
- 中移动2 :
-
高光谱图像分析最常用的波长范围是什么?
特征选择和学习(第2.3节)
- 中移动3 :
-
最常见的波长选择算法是什么?
- RQ - 4 :
-
哪种波长选择算法提供最好的预测性能?
- 中移动5 :
-
波长选择后,哪些学习算法最常见?
空间特征(第2.4节)
- 中移动6 :
-
哪些是最常见的空间特征,哪些参数用于提取这些特征?
- RQ 7 :
-
如何将光谱和空间特征结合起来用于学习模型?
- 中移动8 :
-
研究如何选择代表性图像提取空间特征?
- RQ 9 :
-
结合光谱和空间特征是否能提高预测性能?哪一种特征单独表现最好?
选择标准和搜索策略
Scopus数据库是出版物的主要来源。Scopus提供了比Web of Science等其他学术数据库更广泛的研究选择[32]。Scopus集成了更多的资源,尤其是会议记录,并且仍然是人工管理的,这与Google Scholar不同。脚注1:我们的搜索包括摘要,因为不是所有的出版物都在标题或关键词中提到波长选择。我们使用以下搜索字符串在Scopus数据库中检索出版物的标题、关键词和摘要:
(“高光谱成像”或“光谱成像”或“化学成像”或“成像光谱学”)和(“波长”或“波段”或“波段”或“波长”或“波长”)和(“选择”或“选定”))
虽然搜索字符串包含了高光谱成像和波长选择的多个同义词,但这并不能排除缺少“波长选择”的研究,这意味着搜索结果可能包括不需要的研究。根据表1中列出的标准手动纳入和排除研究。分析仅限于高光谱成像研究的一个子集,波长选择以降低维数。我们没有排除基于语言(如英语、汉语和法语)或发表年份的研究。如果出版物缺乏完整的方法(例如,已发表的摘要),我们仅排除基于出版物类型(例如,会议或同行评议期刊)的研究。
研究选择过程
文献综述的初始检索阶段返回1063项研究。这些文章于2021年10月14日被检索。我们的综述在2022年12月13日更新了166项最新研究,总共有1229项研究。采用表1中定义的选择标准来减少研究总数。图2显示了研究选择过程的流程图。排除了重复研究(n = 2)和会议公告(n = 2),共筛选了1225条记录。接下来,我们在筛选全文结果之前留出17篇评论,留下1208篇出版物。评论被排除在外,因为它们没有提供比较波长选择方法的经验结果或遵循分析图像的方法。
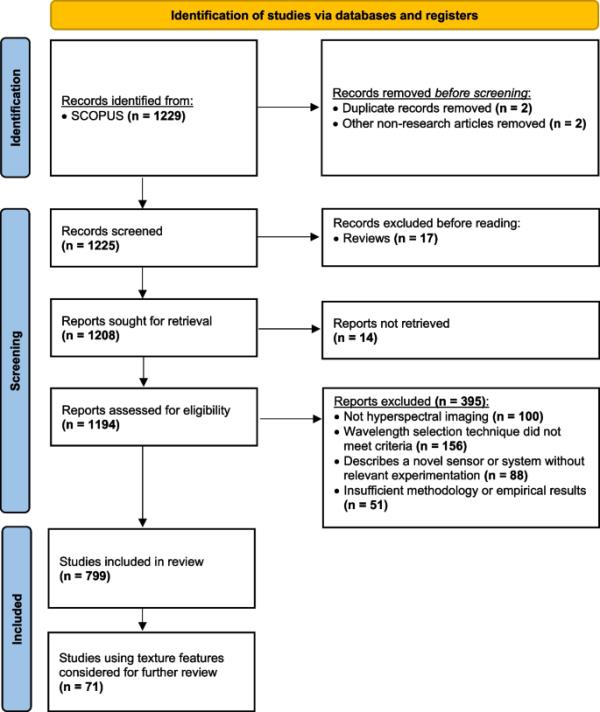
研究选择过程流程图。本文详细介绍了数据库检索、筛选过程和纳入研究的数量,分为两部分
选择标准涉及高光谱成像,波长选择和经验结果。本研究将高光谱成像定义为使用捕获至少90个波长的高光谱传感器获取图像。高光谱成像在文献中通常定义为100个波长或更多。我们对最初捕获超过100个波长但在分析过程中去除噪声带的研究采用宽大处理,将波长总数减少到90到100之间。
第二个标准是波长选择,它被定义为基于算法的特征选择,在不限制大小的情况下选择最优波长的子集(例如将搜索限制在单个波段或一对波段)。这些区别排除了可以对所有波长组合进行强力搜索以选择波长的研究。我们排除了非算法和基于专家知识的波长选择方法,例如手动选择频带比。然而,我们纳入了人类需要手动解释图表以选择波长的方法(例如,主成分图或导数曲线)。
最后的标准是经验结果:每项研究都需要一种透明的方法,将选择的波长与机器学习或其他统计方法结合起来,用于高光谱图像分析。每项研究都要求提供明确的实验结果。该标准排除了未经实验提出新型高光谱系统或传感器的研究,以及很少有细节可以回答我们的研究问题的研究。
我们筛选了1208篇出版物的全文,以确定哪些研究符合我们的纳入标准(表1)。由于摘要中缺乏细节并不是排除标准,因此所有研究都需要进行全文筛选。在这一阶段,395项研究被淘汰。在被淘汰的研究中,156项没有应用适当的波长选择技术,而100项没有研究高光谱图像。最后,有14项研究是研究人员和同事无法访问的。我们通过ResearchGate联系了13项研究的原作者。脚注2:在最初未能联系到的16家公司中,有14家未能及时回复本文。本综述的第一阶段包括799项研究。这些出版物的完整列表可在本手稿的补充材料。
本综述的第二阶段包括62篇英文研究,这些研究从高光谱图像中提取空间特征,以回答第1.1节中定义的空间特征研究问题。整个研究群体(n = 799)和利用空间特征的子集(n = 71)是调查的两组研究。
研究的编码
一位审稿人手动检查每个研究是否符合我们的纳入标准,并在谷歌表格中记录所有相关信息。然后审稿人完成多次审查,一次检查所有研究的一个属性以检查收集到的信息,并且我们的纳入标准被一致地应用。在审查的第一阶段,谷歌翻译足以从非英语研究中提取信息。第二阶段仅限于用英语撰写的研究,以避免由于翻译错误而导致的信息误解。数据收集过程是手动的,因为一些研究无法使用自动化工具读取。
收集每项研究的语言、发表年份和广泛应用领域(如肉类科学或医学成像),用于人口统计学和应用领域分析。从每个研究中收集波长范围和样本量,以回答高光谱研究设计研究问题。在研究的所有高光谱系统中剔除噪声波段(如果适用)后,收集有效波长范围。样本量记录为排除外围样本(如适用)后在研究中成像的唯一物体的数量。
收集的出版物包含200多种波长选择技术和学习算法。从每项研究中,我们收集了波长选择和机器学习技术的逗号分隔列表,以及基于其性能的最佳波长选择方法的有序列表。性能被定义为预测类别或连续测量感兴趣的准确性。最优波长集的性能是基于该子集的最佳学习模型的预测集(测试集)精度来确定的。当出现平局时,验证集随后的校准集精度充当平局打破者。当一种方法明显优于其他方法的子集时,根据它们在预测集上的表现对方法进行排名。如果没有一种方法明显优于其他方法,或者多种方法之间没有比较,我们将最佳方法记录为不确定的。许多研究只应用了一种波长选择方法。在这种情况下,最好的方法被记录为只有一个。
结果用Python脚本制成表格,根据与其他方法的比较次数对波长选择方法进行排名。我们只纳入了七个或更多研究中应用的波长选择技术,并将其他所有技术归为其他类别。例如,如果一项研究应用遗传算法(GA)、连续投影算法(SPA)和回归系数(RC)来选择一个最优子集,并对它们进行排序,我们记录了三种比较:GA优于SPA, GA优于RC, SPA优于RC。
我们根据收集到的以逗号分隔的列表,列出了使用Python脚本使用每种学习算法的研究数量。许多研究已经测试了同一类算法的多种变体,例如随机森林和决策树。为了获得更有价值的见解,我们将研究的数量作为受欢迎程度的衡量标准,而不是每个算法的出现次数,这意味着比较两个版本的支持向量机的研究被视为单个观察。
我们使用一个单独的Google表单,从提取空间特征的研究子集中记录了与空间特征相关的最终研究问题的细节。我们记录了提取的空间特征列表,这些特征提取器的参数,光谱特征与空间特征的性能比较,与单个模型的数据融合性能比较,如何选择代表性特征图像来提取空间特征,以及如何融合光谱-空间特征。我们将数据融合模型是否优于单个模型记录为是、否或不确定。最好的个体特征集被记录为光谱特征,空间特征,不单独比较,或不确定。两者都是根据最佳模型的预测集的准确性来确定的。
所有的研究都需要有关波长选择技术的详细信息,以满足我们的纳入标准。并非收集的所有其他属性都是强制性的。对于每个研究问题,我们忽略了没有说明或不清楚相关属性的研究。只有对空间特征的研究才能回答空间特征的研究问题。由于收集的信息对每项研究的可重复性至关重要,因此缺少数据可能表明发表质量较低。
电子表格存储了本次评审收集的信息,并生成了简单的统计数据(例如计数)。Python脚本提取回答问题所需的其他信息(例如,方法的比较和波长范围图),并用于生成表格和图形。所需的Python库是用于读取数据的PandasFootnote 4,用于创建图形的Footnote 5和MatplotlibFootnote 6。
本研究中的偏见
本综述可能会引入一些来自流行作者或研究小组的研究。一些研究小组可能会对多种高光谱成像应用采用相同的方法。这种不平衡可能会扭曲波长选择、学习算法、相机模型和其他感兴趣的属性对高光谱成像应用最流行的结论。
由于每项研究获得了不同的数据集,并且没有可用的对照组,因此没有方法探讨研究结果之间异质性的原因。没有方法评估由于缺失结果、结果的稳健性或结果的证据体的确定性而导致的偏倚风险。许多波长选择技术的出现存在显著的不平衡。一些波长选择技术已在一小部分研究中使用(例如LASSO[33]),而其他波长选择技术已在数百项研究中得到一致应用(例如SPA[34]和CARS[35])。我们将分析限制在五项以上研究中应用的方法,以减少不常见技术的影响。
目录
摘要 方法 结果 讨论 结论 笔记 参考文献 致谢 作者信息 补充信息 搜索 导航 #####结果
最初的搜索返回了1229篇出版物。在应用选择标准之后,选择了799份相关的出版物进行分析,如下面的小节所述。尽管所有799项研究都为本综述的结论提供了依据,但并非所有研究都被引用。纳入和排除研究的完整列表及其排除原因可在补充材料中获得。
研究的人口学特征
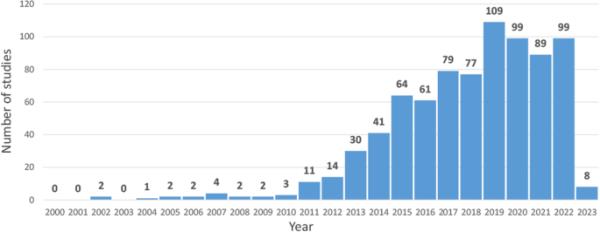
2000年至2022年间纳入本综述的研究数量。研究的数量随着时间的推移而增加。由于对COVID-19大流行的限制研究,近年来出现了下降
根据Scopus提供的分类,纳入了734篇期刊论文和65篇会议论文。在总共799项研究中,发表语言包括646项英语研究,149项中文研究和4项其他语言研究(德语、西班牙语、法语和波斯语)。对每年发表的论文的分析显示,波长选择的高光谱成像研究有所增加(图3)。这一增长可能是由于价格合理的高光谱传感器的可及性增加。2019冠状病毒病大流行可能限制了进入研究实验室的机会,导致研究产出自2020年以来略有下降。
标准高光谱研究设计
样本大小
设计高光谱成像研究的第一个方面是所需样本的数量(rq1)。必须确保每个研究都有足够数量的样本用于训练模型,并有一组代表性的未见样本用于验证。为了比较本综述中包含的高光谱成像研究总体的样本量,我们必须定义一个单一的样本。图像的数量不能代表样本量,因为有些可能包含多个样本(例如,多个玉米粒或水稻粒)。购买或检索的受试者数量可能不可靠,因为研究人员可以从多个子样本中获得测量结果(例如,测量肉鸡胸片的嫩度[36])。因此,我们将样本数量确定为具有相应参考值或类别的感兴趣的个体样本数量。
图4中所示的盒状和须状图在对数尺度上总结了这些数据,这是由于观测结果的偏态;样本数量的中位数为180,中间的50%在105和300之间。均值为424.04个样本,最大值和最小值分别为19,000和1个样本,这表明由于异常值的存在,数据存在明显的偏差。一些研究的样本数量与单幅图像一样少,例如使用印度松树数据集[37,38]进行土地利用分类的研究。有数千个样本的研究通常调查低成本、易于成像的对象,如燕麦、玉米粒或其他类型的种子[39,40,41,42,43,44]。样本数量第二多的研究(15,000个)收集了多年的数据来检测影响葡萄品种的疾病[43]。
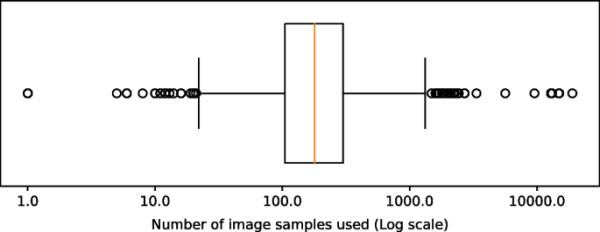
在应用波长选择的高光谱研究中遇到的样本数(对数尺度)。样本数量的中位数为180,中间的50%在105和300之间。异常值需要对数尺度,其中包括使用单个图像的一项研究和使用19,000个样本的另一项研究
一些研究获得了同一受试者跨多个时间戳的图像,以了解损伤症状如何随时间发展[45],或比较治疗前后[46,47]。这样的抽样增加了观察的数量和样本的变化。然而,这只有在没有破坏性分析来检索样本的真值参考值时才有可能。在这些研究中,我们计算的是成像样本的数量,而不是唯一样本的数量。样品的化学分析通常是破坏性的。根据该分析所需材料的数量,测量每个样品的多个属性可能并不总是可能的[48,49,50]。
为了分类,可以将单个样本细分为多个类别的区域,例如检测鸡片上的白色剥落[51],其中单个样本可以看到多个受影响的区域。另一个例子是在同一图像中可以看到多个有缺陷和未受影响的区域。研究水果样品受损的光谱响应的研究人员通常为受损和未受影响的区域定义多个感兴趣的区域[52,53]。总之,大多数研究捕获的样本在105到300之间,但研究类型之间方法的差异使得记录样本量变得困难。
波长范围
本综述研究设计的第二个方面是如何选择合适的波长范围来捕获高光谱图像(rq2)。图5显示了681项研究中研究的波长范围,这些波长范围清楚地表明了它们的传感器范围。根据市场上可用的传感器,三个最常见的范围是可见光/近红外(VIS/NIR: 400-1000 nm),近红外(NIR: 900-1700 nm)和短波红外(SWIR: 900-2500 nm)。具体的兴趣范围取决于应用程序。例如,预测与水分相关的样品属性更适合在红外范围内,因为水吸收更多的光,但当颜料与目标属性相关时,专注于可见光的传感器更合适。
大多数研究集中在其中一个范围,只有50个研究了多个范围。当研究人员将多个传感器组合在一起(以在更广泛的波长范围内检查光谱特征)时,作者从每个传感器提取平均光谱,并将这些向量连接起来,形成一个代表样本的连续光谱向量。然后,研究人员将一个模型与从组合光谱中选择的波长相匹配。由于无法在传感器之间找到对应的像元,本综述中没有研究通过组合多个传感器的数据来提取扩展的逐像元光谱。
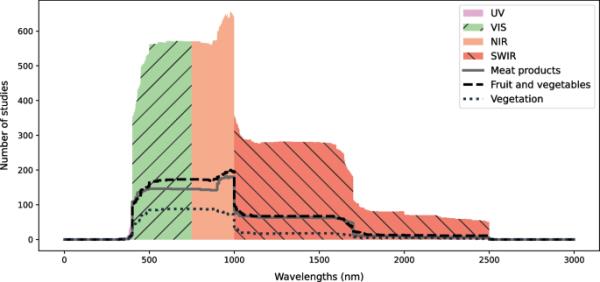
调查每个波长范围的研究数量的直方图
图5显示了由于VIS/NIR和其他传感器之间的重叠,在感兴趣的波长范围内约900-1000 nm的峰值。由于这些传感器的可及性[54],以及该波长范围内探测器涂层的较低成本[7],VIS/NIR范围是最常见的。在这些不同量程之间,基于样品类型的传感器选择没有显着差异。图上的线条显示,肉制品研究SWIR和VIS/NIR的比例与水果和蔬菜相关研究的比例大致相同。
功能selecTion和机器学习
波长选择
先前对波长选择技术的综述已经根据方法如何找到最佳特征将该领域分为三类[29]。这些类别是过滤器、嵌入和包装器方法。滤波方法对特征重要性分数应用阈值以选择最佳波长。滤波方法的例子包括回归系数和投影中的可变重要性(VIP)。嵌入式方法集成了学习和特征选择,如LASSO回归[33]和决策树。包装方法是最流行的一类,它们通过迭代更新波长子集和拟合模型来评估性能。包装方法包括连续投影算法(SPA)[34]和遗传算法[55]。我们还提出了第四类技术,即手动选择方法,其中算法提供专家可以解释的输出以选择关键波长。主成分分析荷载图就是这种方法的一个例子。研究人员通常确定波峰/波谷的点作为重要波长。
我们将这种分类扩展到波长选择方法的其他两个类别:串联和基于间隔的方法。串联方法将多个选择算法串在一起,从先前选择的子集中选择重要特征,而基于间隔的方法选择波长的信息间隔,通常是手动确定的宽度。串联方法可以结合多种算法的优点,如UVE和SPA。UVE存在多重共线性问题,SPA可能选择无信息变量。UVE-SPA首先去除无信息波长,SPA去除多重共线性最小的变量[16]。在表2中,我们将最流行的波长选择技术分为这些类别,并引用了最近使用每种技术的英语研究(RQ 3)。
表3提供了在该地区应用的波长选择技术之间的详尽比较(RQ 4)。这些表列出了所选方法(行)优于比较方法(列)的研究数量。当表中显示“只有一个”时,它计算了比较方法是唯一波长选择方法的研究数量。“不确定”一栏表示应用波长选择技术的研究数量,其中每种方法的排名都不清楚。最后,“未比较”行提供了使用该方法未与其他方法进行比较的研究的数量。从这些表中,我们发现有一组明确的常用方法:连续预测算法(SPA)[34]、竞争自适应重加权抽样(CARS)[35]、回归系数(RC)[60]和主成分分析(PCA)加载。在这些技术中,CARS通常是最好的方法。在76项比较中,car在50项中表现优于SPA,其中一项优于另一项。
在122项研究中,研究人员手工检查了PCA加载图中的波峰和波谷,以选择关键波长。79项研究将其作为唯一的波长选择技术,59项研究将其与其他方法进行比较。PCA加载在14个比较中有4个优于SPA,在6个比较中有1个优于CARS,在7个比较中有3个优于回归系数,其中一种方法更好。PCA加载是性能最差的技术之一,尽管它是最流行的方法之一。
本综述中发现的最常见和一致的方法是CARS和SPA方法。仅在CARS算法表现不佳的比较方法中,拼接方法和投影变重要度(VIP)方法表现不佳。串联和基于间隔的方法,UVE和CARS优于SPA,而SPA在所有其他比较中表现良好。回归系数是89项研究中使用的唯一波长选择方法,在57项研究中,研究人员将其与其他方法进行了比较,结果表明它表现不佳。回归系数的性能通过与遗传算法(7次比较中有2次最佳)、CARS(16次比较中有5次最佳)和SPA(30次比较中有11次最佳)的比较来证明。与PCA加载一样,回归系数是一种简单的特征选择方法,这使得它比那些在不同编程语言的标准库中不可用或内置于商业软件中的新颖方法更受欢迎。
对于在超过五项研究中使用的两种串联方法,很少与其他技术进行比较。包括这些方法的研究经常将它们与其他串联方法进行比较[129,130]。CARS-SPA和UVE-SPA表现良好,但分别仅在20和15项研究中应用。CARS-SPA的性能最高,在15次比较中有10次优于SPA,与CARS的性能相当(16次比较中有8次优于SPA)。UVE-SPA同样表现良好,但表现不如其他串联方法,如CARS-SPA(五项比较中有两项最好)。UVE- spa分别被CARS和UVE超越(分别在9次比较中的2次和7次比较中的1次中表现最佳)。
最常见的基于区间的方法是区间偏最小二乘(iPLS)[89],区间vissa (iVISSA)[103],协同区间偏最小二乘(siPLS)[123]和区间随机青蛙(iRF)[105],经常相互比较。这些方法将全谱划分为等距分区,并将回归模型拟合到区间[91]。这些方法没有足够的比较来得出哪个基于区间的方法是最好的,并且它们相对于单特征方法的性能通常很差。
许多研究提出了一种新的波长选择方法,并将其与一小部分最常用的方法进行了比较,同时声称其性能优越。需要在多个数据集上与更广泛的技术进行比较,以对其性能进行基准测试。由于应用每种方法的研究不超过5个,我们将这些方法分组到表3的“其他”列中。据我们所知,没有标准化的基准数据集可用于波长选择。
其他流行的波长选择方法包括遗传算法[55]、随机蛙[70]、无信息变量消除[67]和投影中的变量重要性[60]。遗传算法表现良好,但由于许多超参数必须手动设置,因此不容易与该算法进行比较。
机器学习方法
模型创建的最后一步是将模型与选定的波长拟合。在这里,我们列出了应用于所选波长(rq5)的最常见的机器学习和统计模型。偏最小二乘(PLS)是波长选择后分析高光谱数据最常用的学习算法。共有470项研究选择了PLS的变体,最常见的变体是用于回归的偏最小二乘回归(PLSR)和用于分类的偏最小二乘判别分析(PLS- da)。先前的综述报道了PLSR和PLS-DA的高利用率[131]。PLS不是直接对变量进行操作,而是提取一组具有最佳预测性能的潜在变量[21]。74项研究应用了一种更直接的多元线性回归(MLR),它可以将一个简单的线性方程拟合到观察到的数据中。MLR与波长之间的高度多重共线性作斗争[132],这使得先前的波长选择很重要。MLR的优点是结果的可解释性,而潜在变量或主成分的含义是不明确的。在333项研究中,第二常见的算法是支持向量机(SVM)[133],其最常见的变体是最小二乘支持向量机(LS-SVM)和支持向量回归(SVR)。
各种研究应用了人工神经网络(ANN)架构的变体,如反向传播神经网络(BPNN)[134]、极限学习机(ELM)[135]、堆叠自编码器(SAE)和卷积神经网络(CNN)[136]。这些机器学习方法应用一系列处理层来提取更高级的特征,通常被称为深度学习方法。非线性方法如人工神经网络和支持向量机对于因变量和自变量之间的复杂关系建模是有价值的。这些非线性方法具有较高的计算复杂度[10]。只有少数研究将深度学习应用于食品应用的高光谱成像,因为收集具有相应参考(地面真值)测量的大型数据集需要时间和成本[8]。很少有研究(n = 20)将卷积神经网络与波长选择结合起来,尽管它们在高光谱成像以外的计算机视觉中很受欢迎,但自2022年以来,这些技术变得越来越普遍[57,137,138,139]。由于大数据和小样本量的挑战,CNN方法通常对光谱响应使用一维滤波器,而不是对高光谱图像使用二维或三维滤波器。表4显示了本研究发现的每种学习算法的计数。
在67项研究中发现了决策树,包括随机森林和分类回归树(CART)等变体。k近邻(KNN)是一种基于样本与其他标记样本的距离对样本进行分类的简单方法。由于需要的邻域比较的数量,对于较大的数据集,KNN的计算成本会更高。投影方法,如线性判别分析(LDA)和主成分分析(PCA),通过将剩余波长投影到新的轴上来区分数据中的类别,以最大限度地提高方差和类别可分性。采用主成分回归(PCR)代替主成分分析进行回归分析。53项研究使用LDA, 26项研究选择PCA。在被调查的799项研究中,有77项比较了不符合这些类别的学习算法。
空间特性
空间描述符(图像纹理描述符)提供了像素的空间排列信息,而光谱信息描述了光如何与样本相互作用。如前所述,许多综述承认将空间特征作为独立的建模变量有助于提高模型的预测性能[22]。空间信息包括总结强度分布的统计特征,如统计矩,高阶空间描述符(统计)描述像素组的分布,如灰度共生矩阵的对。空间特征还可能包括局部邻域操作,如局部二元模式(LBP)[140],或描述感兴趣区域形状的形状特征。本节描述了从高光谱图像中提取空间特征的不同技术(rq6),选择特征图像的方法(rq8),结合空间特征的模型的预测性能(rq9),以及如何将空间特征与光谱特征结合起来的研究(rq7)。
空间特征criptors
在799项研究中,有71项研究包括空间特征和用于高光谱图像分析的波长选择。表5提供了这些研究的细分,回答了rq6。最受欢迎的空间特征是在71项研究中的41项中发现的灰度共生矩阵(GLCM)纹理描述符。GLCM描述符(也称为Haralick特征)通过创建在给定角度()和距离(d)处像素灰度值联合出现的概率矩阵来描述二维特征图像[202]。
Haralick等人[202,203]描述了14个特征,将GLCM矩阵归纳为纹理描述符。Clausi[204]、Soh和Tsatsoulis[205]等研究进一步扩展了这组特征。最常见的五个特征是:对比/惯性矩(n = 38)、能量/均匀性/角秒矩(n = 38)、相关性(n = 36)、均匀性/逆差矩(n = 35)和熵(n = 19)。有四项研究调查了这五个核心特征之外的特征[171,178,184,194],但有两项研究没有提供关于提取特征的足够信息。最早将空间特征与波长选择相结合的研究之一[194]提取了22个GLCM特征,包括多种选择特征图像的方法。然而,这些研究并没有检查每个特征的有效性。
GLCM的主要参数是测量像元相关性的角度和距离。通常,研究选择0°、45°、90°和135°四个角度来描述对角线、垂直和水平的关系,以创建GLCM矩阵。不同的角度和距离产生不同的矩阵。11项研究平均了四个方向上的描述符,以产生一个旋转不变的描述符。许多研究没有说明它们是在多个角度(n = 16)上平均,还是没有在多个角度(n = 8)上平均,或者只使用一个角度(n = 5)。对于距离参数,典型的方法是基于一个像素的距离创建矩阵。很少有研究考察更大范围的距离,如1到10个像素[201]或1到5个像素[164,190]。因为我们可以在受控环境中固定样品和传感器之间的距离,所以单一的距离应该足够了。未来的研究应该使用多个距离来确定最佳效果。
第二流行的空间特征提取方法是灰度梯度共现矩阵(GLGCM) [206] (n = 11)。与GLCM类似,GLGCM通过描述图像的灰度梯度来捕获空间图像内容的二阶统计量。GLGCM矩阵表示具有给定灰度值和梯度的像素之间出现的相对频率。数据融合模型在提取GLGCM特征的所有研究中都优于单一模态模型,并将融合模型与单个模型进行比较(n = 10)。GLGCM具有比GLCM更大的特征集,描述了梯度的主导地位和分布,以及像素梯度和灰度的熵、平均值、标准差、不对称性和非均匀性。GLCM和GLGCM的受欢迎程度与以往的综述一致[1,14]。
另一种空间特征提取方法是局部二进制模式(LBP)[169, 175, 182],其中每个像素与其水平、垂直和对角线相邻像素进行比较,得到8位二进制代码[140]。二进制码中的每个位置描述相邻像素值比目标像素大(1)还是小(0)。高光谱图像的LBP特征有不同的结果。一项研究从RGB图像中提取LBP特征,在没有数据融合的情况下对冷冻烧焦鲑鱼进行分类,发现基于光谱的模型在区分类别方面表现更好[175]。另一项研究发现,GLGCM和GLCM在没有数据融合的情况下明显优于LBP[169]。
GLCM、GLGCM和LBP基于像素对之间的关系提供二阶统计量[207]。一些研究基于特征图像中强度的直方图提取一阶统计量,如直方图描述符。直方图统计总结了图像的灰度值分布,而不考虑像素之间的空间相互作用。从这些灰度直方图中提取的最常见特征是均值、均匀性、熵、标准差和三矩(偏度)[186,195,208],以及峰度、能量、平滑度、对比度、一致性和粗糙度[141,149,154,178,180]。一项研究将特征选择应用于预先计算的空间特征,发现选择算法没有选择基于直方图的特征来预测牛肉嫩度[182]。其他研究发现,直方图统计比GLCM特征[178]或形状描述符[186]更能提高模型的准确性。在另一项研究中,GLCM显著优于直方图统计[51]。
五项研究探讨了Gabor滤波器用于高光谱图像的空间特征提取[146,165,170,182,191]。Gabor滤波器是用于纹理分析的线性滤波器,它使用由高斯和正弦项组合产生的核进行卷积。结果通常在多个角度上平均,以获得旋转不变的描述符[146,165]。
在2020年之前,只有一项研究使用卷积神经网络(CNN)提取空间特征[153]。该CNN架构使用了两个分支,一个是用一维CNN提取光谱特征,另一个是用二维CNN提取空间特征。该模型将提取的用于分类的特征向量拼接成单个特征向量。使用CNN在第一层学习到的权重来评估特征重要性,以选择最佳波长。此后,更先进的二维CNN架构被用于利用图像中的空间信息[84,143]。一项研究应用了流行的物体检测算法YOLOv3算法[209]对苹果缺陷进行检测[139]。
最后常见的空间特征提取方法是形态/形状特征。这些方法用形状特征描述了包含样本的感兴趣区域的轮廓。形状特征只需要样品的ROI掩码。提取的典型特征是面积、周长、长、短轴长度和偏心率。由于形状与品种的相关性,提取形状特征的研究在种子[197]和黑豆[181]的品种鉴别中取得了较好的效果。在这两种情况下,基于光谱特征训练的模型的精度都优于空间特征,并且数据融合模型进一步改善了结果。也有研究利用边缘检测算法检测裂缝,利用形态学特征检测散落的蛋黄[142]。
其他较少使用的空间特征提取包括灰度游长矩阵分析[183]、宽线检测器[146,191]和基于小波的变换,如离散小波变换(DWT)[96, 192]和离散余弦变换[172]。
选择特征图像
每种特征提取方法都需要一幅图像来构成空间特征描述符的基础。最常用的方法是从全高光谱图像或预先选定波长的主成分(PC)评分图像中提取特征。在提取空间特征之前选择最佳波长的计算量较小。预选最佳波长的前提是,具有重要光谱信息的波长也携带重要的空间信息。48项研究采用在提取空间特征前选择最佳波长的方法。另一种方法是从高光谱图像内的每个波长提取空间特征,然后应用特征选择将特征从减少的频带数量(后选)中减少到一组最优特征。有两项研究直接从所有波长中提取具有重要空间特征的波段[146,188]。其他研究应用特征选择从选定的或完整的特征集中选择信息特征[144,165,173,191]。
25项研究选择PC分数图像作为特征图像。尽管在整个光谱中提取纹理描述符是可能的,但这增加了计算复杂度,使其在实时系统中不可行。一项研究利用了所有可用波长的空间特征,而没有进行特征选择[177],另外五项研究要么从高光谱传感器创建RGB图像,要么从副相机捕获RGB图像[84,142,166,175,201]。所选择的特征图像列在表5的特征图像列中。
数据融合
数据融合有三个层次,用于组合来自不同特征空间的特征[210]。像素级融合将多个模态作为共配输入集成到单个特征提取模型中,特征级融合在提取特征特征后将特征进行组合,决策级融合将多个模型输出与提取的特征拟合后进行组合。几乎所有考虑空间特征的研究都将光谱和空间特征结合起来,并进行特征级融合,其中一些基于cnn的模型在像素级整合了光谱-空间信息[84,139]。他们首先从图像中提取特征,结合光谱和空间特征,然后将模型拟合到融合的特征向量上。通过在光谱和空间特征上训练独立模型,然后使用元模型对独立模型的决策进行融合,可以实现决策级融合。经过特征级融合训练的模型可以包含单个特征之间的相互作用,这是决策级融合模型所不能做到的。特征级融合避免了像素级融合中高维特征提取的计算负担。
当两个不同波长范围的高光谱传感器数据融合时,像素级融合是可行的。所有合并多个传感器数据的研究都是从每个传感器的ROI中提取平均光谱,并将其合并为单个光谱进行建模,这也被认为是特征级融合。然而,感兴趣的区域可以一起注册,以组合每个像素的多个波长范围。
均值归一化通常应用于不同模态(光谱和各种类型的空间描述符)的特征,以克服特征之间的差异所带来的问题[154,165,171,180,183,185,189]。归一化通过其均值和标准差重新缩放训练集中的每个特征(校准),使所有特征具有可比较的大小。
表演
37项将空间特征纳入其特征集中的研究发现,仅对光谱特征进行训练的模型的预测性能优于仅对空间特征进行训练的模型(表5)。只有5项研究发现空间特征比光谱特征更有助于预测属性,29项研究未能比较这两种方法,从而使我们能够确定哪种模型最有效。然而,所选择的模型也会影响结果。我们使用的性能指标是最佳模型的准确性。当光谱和空间特征结合使用时,我们发现大多数研究(n = 40)将光谱和空间特征结合使用比单独使用空间或光谱特征效果更好。在6项研究中,个体模型优于数据融合模型。最后,有25项研究没有将单个模型与光谱-空间融合模型进行比较。
在这些外围研究中,空间特征往往更适合这个问题,因为它们对应于清晰可见的纹理指标。例如,可以使用宽线检测器检测猪肉大理石纹,以预测肌肉内脂肪[146]。其他与猪肉评估相关的研究发现,Gabor和GLGCM特征在预测总挥发性碱基氮含量(TVB-N)[165]和新鲜度[187]方面分别优于光谱特征。在茶叶品种分类[167]和茶叶含水量预测[196]方面,GLCM特征优于光谱特征。这些研究表明,在预测感兴趣的属性方面,空间特征可能比光谱特征更有价值。
研究可能发现数据融合模型的性能较差,因为它们没有包括与预测变量相关的空间特征。一项研究发现,在对玉米种子质量进行分类时,校准集和预测集的性能显著下降,这可能表明该模型对数据过拟合[154]。当模型在校准集中识别出在预测数据集中不太普遍的趋势时,就会发生过拟合。另一项研究报告了光谱和数据融合模型在预测鲑鱼嫩度方面的类似预测性能[190]。GLCM特征不能帮助预测青枣的冻害等级[162]。在这些研究中,空间特征可能不适合特定的问题,或者根据光谱数据选择的波长可能不合适。
下载原文档:https://link.springer.com/content/pdf/10.1007/s11694-023-02044-x.pdf


