


摘要
本研究提出了一种改进现有凹点检测方法的方法,作为有效分割图像中重叠物体的第一步。该方法依赖于分析物体轮廓的曲率。这种方法包括三个主要步骤。首先对原始图像进行预处理,得到各轮廓点处的曲率值;其次,选择曲率较高的区域,并采用递归算法对先前选择的区域进行细化;最后,通过分析相邻区域的相对位置,得到每个区域的凹点。此外,实验结果表明,改进凹点的检测可以更好地划分聚类。为了评估凹点检测算法的质量,构建了一个模拟重叠物体存在的合成数据集。该数据集包含凹点的精确位置,作为评估的基础真值。作为一个案例研究,性能的一个著名的应用程序,如分裂重叠细胞的图像从镰状细胞性贫血患者的外周血涂片样本,评估。我们使用该方法检测细胞簇中的凹点,然后通过椭圆拟合对这些簇进行分离。
1 介绍
图像中重叠物体的分割可以作为各种生物医学和工业应用的第一步,从血细胞研究[11]和颗粒分析[28]到磁共振乳房图像的分割[6]。
在这些应用中,通常需要使用单个对象的单一特征对其进行分析。存在重叠物体的图像区域减少了图像中某些物体的可用信息,即遮挡区域。这些遮挡区给分割过程带来了巨大的复杂性,使其成为一个具有挑战性的问题,可以从多个角度解决,并且仍然是开放的。
为解决这一问题提出了若干策略。分水岭算法[18,22,25]和水平集[4]广泛用于重叠对象之间边界明确的场景。然而,这些方法无法分离具有均匀强度值的重叠目标,因为初始标记的检测不准确,导致边界扩散。
为了克服这些困难,可以采用一种基于凹点检测的分割方法。这些点表示不同对象的轮廓重叠的位置,同时也是重叠的对象从一个子对象变为另一个子对象的位置。一旦检测到凹点,就可以使用多种技术来划分物体。凹点检测的优点是它对尺度、颜色、旋转和方向是不变的。
此外,与深度学习方法不同,基于凹点检测的方法可以在不使用大型数据集或输入图像大小约束的情况下进行良好的分割。此外,对重叠物体进行分割的凹点检测可以认为是透明的,因为它具有可模拟性、可分解性和算法透明性[1]。
凹点检测越好,聚类划分越好。因此,我们提出了一种新的方法,与最先进的方法相比,它提高了凹点检测的精度。该方法基于对轮廓曲率的分析。为了评估我们的方法,我们构建了一个合成数据集来模拟重叠的物体,并提供凹点的位置作为地面真值。我们使用该数据集比较了所提出方法与最先进方法的检测能力和空间精度。作为一个案例研究,我们评估了凹点检测器的一个众所周知的应用:在镰状细胞病(SCD)患者外周血涂片样本(RBC)的显微图像中重叠细胞的分裂。注意,该算法并不局限于细胞分割;它可以用于其他需要分离重叠对象的应用程序。
本文的其余部分组织如下:在下一节中,我们将描述相关工作。在第3节中,我们解释了提出的有效检测凹点的方法。第4节指定了实验环境并描述了使用的数据集。第5节讨论了将该方法应用于目标簇的合成图像和真实图像后得到的结果和对比实验。最后,在第六节中,我们给出了我们工作的结论。
2 相关工作
在最先进的方法中,我们可以找到基于凹点检测的多种方法。根据Zafari等人[31]提出的分类方法。然而,通过为其他方法添加一个类别,我们将这些方法分为四类:骨架,弦,多边形近似,曲率和其他。
2.1 骨架
基于骨架的方法利用关于边界及其中轴线的信息来检测凹点。Song和Wang[24]将凹点定义为物体边界与其中轴线之间距离的局部最小值。采用基于二值细化算法的迭代算法获得中间轴,然后采用剪枝法。Samma等人[23]通过应用扩张背景图像的形态梯度骨架得到的物体边界相交来识别凹点。
这些方法需要较大的曲率变化来检测现有的凹点。因此,基于骨架的方法在光滑曲率的轮廓物体上往往失败。
2.2 和弦
和弦方法使用重叠对象的凸壳区域的边界。这个边界由一个有限的弯曲段组成,每个弯曲段都是物体轮廓C的一个弧,或者是端点在C上的一条线,称为弦。如果Li是其中的一条线(弦),Ci是端点相同的C的一段,那么Li和Ci的并集产生一条简单的闭合曲线,这就决定了凸性缺陷。弦法利用凸壳轮廓和凸缺陷来检测凹点。这些方法的主要思想是识别轮廓和凹凸缺陷之间的最远点。
多解使用弦分析提取凸点。Farhan等人[9]提出了一种通过对轮廓点拟合的直线进行求值来获取凹点的方法,如果两个轮廓点的连接线不在物体内部,则检测凹点。Kumar等人[15]提出了凹区域的边界及其对应的凸包弦。凹点定义为凹区域边界上与凸壳弦的垂直距离最大的点。类似地,Yeo等人[29]和LaTorre等人[16]对凹凸缺陷与轮廓之间的区域采用了多重约束来确定其质量。
Chord方法假设每个凸性缺陷只存在一个凹点,但在包含两个以上对象的聚类中,这个假设并不总是成立,因此,一些凹点会被漏检。
2.3 多边形近似
多边形逼近是一组通过一系列优势点来表示物体轮廓的方法。这些方法的目的是通过接近简单物体的轮廓来去除噪声。
Bai等人[2]开发了一类新的算法来遵循这种近似。他们的算法分析了一组等高线点和连接其极值的直线之间的差异。距离这条先前定义的线很远的点被认为是优势点。Chaves等[5]采用著名的RDP (RDP - douglas - peucker)[8]算法对轮廓进行近似,并在轮廓处利用梯度方向上的条件检测凹点。Zafari等人在[32]中提出了类似的方法来检测这些点,其中作者提出了一种无参数凹点检测来提取优势点。他们使用[33]中描述的基于连续优势点的标量积的条件选择凹点。
同样的作者[30]使用了[14]中提出的曲率尺度空间的改进版本来寻找兴趣点。最后,对它们进行凹点和凸点的区分。
Zhang等人[35]与[30]类似,使用修正版本的曲率尺度空间来近似物体。通过应用前面描述的目标逼近算法,他们获得了一组优势点,并从中识别凹点。通过评估这些优势点的角度变化来检测凹点,并使用arctan准则评估这些角度变化。角度变化大于阈值的点被分类为凹点。
这些方法是高度参数化的,对对象大小的变化不具有鲁棒性。这些方法的另一个限制是它们会变形原始轮廓以简化它。这种近似是在凹点位置缺乏精度和轮廓光滑性之间的权衡。这种权衡影响了最终结果。
2.4 曲率
属于这一类的方法将凹点识别为曲率的局部极值。曲线上各点qi = (xi,yi)处的曲率κ计算为:
(1)其中xi和yi为等高线点坐标。
Wen等人[27]通过使用高斯导数对边界进行卷积来计算导数。González-Hidalgo等人[11]使用k曲率和k斜率来近似曲率的值。优势点,即曲率最大的点,可以位于轮廓的凹区和凸区。在[31]中描述了三种不同的启发式方法来检测凹点。
当多个凹点位于小区域时,这些方法往往失败。造成这种情况的主要原因是由于曲率值的近似造成了精度的损失。另一个问题是噪声的存在,它往往被识别为曲率的变化,解决这个问题的一种方法是使用更粗略的近似。
2.5 其他方法
尽管Zafari等人提出了分类方法[31],但存在其他技术来确定不属于上述任何类别的凹点。下面描述了其中一些研究。
Fernández等人[10]为轮廓定义了一个滑动窗口,并计算了该窗口中属于物体的像素和属于背景的像素的比例。这个比例决定了在评估点存在的凹凸的可能性。他等人[13]将这种方法应用于三维空间。在凹度较高的情况下,获得了最佳效果。该方法对物体大小的变化高度敏感,存在噪声时精度降低。这两个问题是由于该方法缺乏通用性而造成的。
Wang等[26]提出了一种瓶颈检测方法。他们将瓶颈定义为两个点的集合,这两个点使欧几里得距离最小,并使等高线上的距离最大。定义瓶颈的点集是凹点。集群中可能存在多个瓶颈。该算法无法确定属于集群的元素个数,元素个数是该算法的超参数。另一个限制是他们没有考虑具有奇数个凹点的聚类。
Zhang和Li[34]提出了一种采用两步算法确定凹点的方法。首先,他们使用Harris角检测器检测一组候选点[12]。其次,他们使用两种不同的算法选择凹点:一种用于明显凹点,另一种用于不确定凹点。他们的算法有很多参数。这种高数量的参数有两个不同的结果:一方面,该方法对重叠对象的特征高度可调;另一方面,如此多的参数导致算法的高复杂性。
目录
摘要 1 介绍 2 相关工作 3.方法 4 实验装置 5 结果与讨论 6 结论 参考文献 致谢 作者信息 道德声明 相关的内容 搜索 导航 #####3.方法
受当前最先进的方法性能的激励,为了提高在分离重叠物体这一具有挑战性的任务上的结果,我们提出了一种基于González-Hidalgo等人[11]工作的凹点检测新方法。整个过程如图1所示。
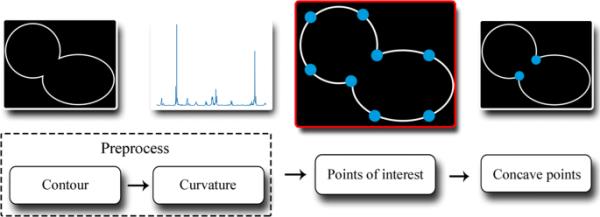
提出了一种从轮廓图中获取凹点的方法
3.1 Pre-procesing
我们使用分割算法从图像中获取目标。根据数据的复杂性,我们可以使用不同的技术:从Otsu[20],一种更简单的非参数阈值技术,到更复杂的方法,如Chan-Vese[3],需要参数化。一旦对目标进行分割,我们获得其轮廓,并使用[8]提出的RDP算法去除分割技术产生的噪声。最后,我们使用一种众所周知的称为k曲率的技术来计算每个点的曲率[21]。这种技术将每个点的曲率视为其斜率的差值。k曲率是可分离的,这允许我们对每个方向独立地进行计算。
3.2 兴趣点
在本节中,我们定义了一种方法,通过分析每个轮廓点的曲率来找到感兴趣的点,这些点可以是凹点或凸点,在下一步中,我们将识别凹点。
获得兴趣点的第一步是确定包括曲率最高的点在内的连续点的子集。我们把这些子集称为兴趣区域。所有属于感兴趣区域(ROI)的点都具有大于某个阈值的曲率,并由它们的起点和终点定义。确定感兴趣区域的过程是下面描述的递归过程,它提供感兴趣区域的列表,并确保在每个ROI中存在感兴趣点。
设C为轮廓点的集合,t为曲率值的初始阈值。我们还定义了另外两个阈值来控制感兴趣区域的长度,即lmin和lmax。lmin值的目的是避免区域数量过多,减少噪声对目标轮廓的影响。lmax值对于防止兴趣点位于过大的区域是有用的,因为我们感兴趣的是从每个区域中只提取一个凹点。这两个参数的最优值与算法处理的对象的大小密切相关。确定这些值的过程高度依赖于具体问题。第4.3节描述了确定两个不同问题的这些值的过程。允许我们检测感兴趣区域的递归过程如下:
步骤1:取轮廓点C,构建感兴趣区域列表l_regions,选择曲率大于t的所有相邻点的不重叠集合,必要时更新t。原始图像如图2a所示。图2b描述了检测到的感兴趣区域列表,不同的感兴趣区域用不同的颜色标记。

确定感兴趣区域的连续步骤。(a)原始图像。(b)步骤1中检测到的感兴趣区域。不同的兴趣区域用不同的颜色标记。(c)步骤1中检测到的感兴趣区域的细节。(d)递归步骤2检测到的感兴趣区域。(e)步骤2的细节
第二步:设r是l_regions中感兴趣的区域,我们用长度表示为r。本研究考虑了三种情况:
-
情形1:如果lmin≤r≤lmax,我们继续下一个感兴趣的区域。
-
情况2:如果r > lmax,我们带r和t + δt回到步骤1。我们用划分r的区域更新了l_regions, r从列表中删除。
-
情形3:如果r < lmin,我们将区域r和它最近的区域结合起来。也就是说,我们确定了rclose,使得d(r,rclose) < k,其中k是计算k曲率所允许的位移。设rnew = r∪rclose为新区域。
-
如果r (rnew) > lmin,我们用r (rnew)和t + δt返回步骤1。如有必要,我们更新了l_regions。
-
如果r (rnew) < lmin,我们用rnew代替r移动到情形3。
-
当l_regions中所有感兴趣的区域的长度在lmin和lmax之间时,进程结束。图2给出了检测区域的最终列表。如前所述,不同的感兴趣区域用不同的颜色标记。此外,在图2c中,显示了一个初始感兴趣区域的放大视图,在图2e中,描述了最终状态。如图所示,初始感兴趣的区域被分成两个新的区域,每个区域包含一个感兴趣的点。
经过这个递归过程,我们得到了一个感兴趣区域的列表,其中每个区域包含一个感兴趣点,即凹点或凸点。最后,我们为每个感兴趣的区域确定了一个兴趣点。我们使用曲率的加权中值来定位它们,因为这是一种众所周知的技术,它假设感兴趣的点位于区域的中心附近;然而,这个中心位置不是一个完美的位置,可以改进。
3.3 co的选择ncave点
在确定了一组兴趣点之后,我们继续检测凹点。算法的这一部分是基于对每个点的邻域相对位置的分析[11],为了完整起见,我们对此进行了更详细的解释。分类阶段包括以下三个步骤:
- 1.
确定两个k邻点:我们在轮廓上选择两个点,它们相对于兴趣点的距离分别为k和- k。这一步骤如图3a所示。
- 2.
k个邻居之间直线的定义:我们在上一步选择的点之间构造了一条直线,见图3b。
- 3.
线的中点:如果先前定义的线的中点在对象之外,我们将一个点分类为凹;否则,该点被分类为凸点。如图3c。
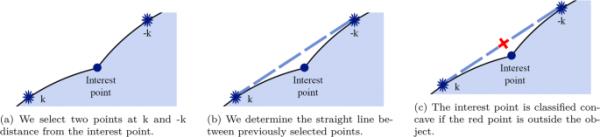
区分凹点和凸点的步骤
4 实验装置
实验设置旨在评估凹点检测器与现有方法的性能,并证明更好的凹点检测意味着更好的重叠目标分割。
4.1 数据集
本研究使用了两组图像。一方面,我们创建了一组合成图像,我们称之为OverArt数据集。它包含2000张图像,每张图像都有三个重叠的物体,并以注释的凹点作为底色。另一方面,我们使用了来自González-Hidalgo等人[11]的真实图像的红细胞idb2数据集,它包含了50张镰状细胞性贫血患者外周血涂片样本的图像。我们使用该数据集检验凹点检测器方法的空间精度是否影响重叠目标分割的结果。
以下4.4.1OverArt数据集
我们生成了OverArt数据集,以获得重叠物体上凹点的地面真相。数据集中的每张图像都包含一个由三个重叠椭圆组成的簇。我们放置了三个椭圆,以模拟显微镜图像中红细胞的真实情况。
代码可在https://github.com/expainingAI/overArt上获得。本研究使用的图像数据集选择n42作为随机种子创建。
图4显示了来自该数据集的三个不同示例。
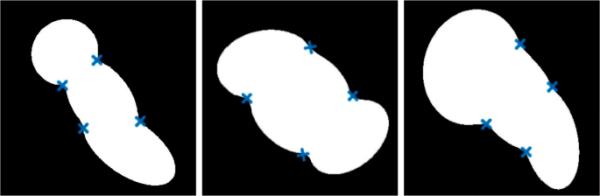
来自OverArt数据集的三个例子。蓝色是凹点,白色是由三个重叠的椭圆定义的簇
每个图像的椭圆由三个参数定义:旋转、透镜直径大小和中心。这些值是使用表1中列出的一组约束随机生成的。
为了构造每个聚类,我们将第一个椭圆定位在图像的中心。另外两个椭圆的位置与第一个椭圆有关。我们在由到第一个椭圆中心的最小和最大距离定义的区域内随机选择第二个椭圆的位置。最后,我们遵循与第三个椭圆相同的过程,将其随机放置在由到第一和第二个椭圆中心的最小和最大距离定义的区域内。
为了比较不同方法寻找凹点的精度,我们需要凹点位置的地面真实值。我们计算了这个值并将其添加到数据集中。凹点被定义为两个或多个椭圆相交的位置,并且必须位于定义重叠区域的轮廓上。
重叠对象由椭圆方程定义,见(2)和(3)。对于数据集的每张图像,我们通过解析求解(4)获得所有凹点的位置。
(2) (3) (4)其中x和y是未知变量,centerx, centy定义了椭圆的中心点,φ是水平轴与椭圆角之间的角度。最后,a和b表示半轴。
4.1.2 ErythrocitesIDB2数据集
在本研究中,我们使用了从红细胞idb2采集的血涂片的显微图像[11],可在http://k1.fpubli.cc/file/upload/202308/16/cs4eojztzmf上获得。这些图像包括镰状细胞贫血患者的外周血涂片样本,由古巴圣地亚哥“Juan Bruno Zayas博士”总医院的专家分类。采用专家准则作为专家方法来验证分类方法的结果。
镰状细胞病(SCD)患者的特征是红细胞呈镰状或半月形,而不是正常细胞光滑的圆形。为了确认SCD的诊断,外周血涂片样本通过显微镜检查镰状红细胞的存在,并将其频率与正常红细胞的频率进行比较。外周血涂片样品中经常含有重叠或聚集的细胞,样品制备过程会影响所研究图像中重叠红细胞的数量。临床实验室通常使用拖拽技术制备血液样本进行显微镜分析,在拖拽技术中,由于扩散过程,样品中可以明显看到更多的细胞群[11]。
每张图像都由医学专家标记。有50张不同细胞数的图像(见图5),这组图像包含2748个细胞。这些细胞属于医学专家定义的三类。这些是圆形的,拉长的,和其他,如图6所示。
来自红细胞idb2数据集的镰状细胞性贫血患者样本
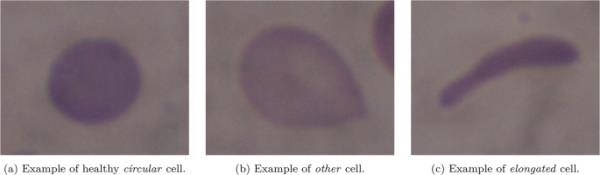
ErythrocitesIDB2数据集中出现的三种类型的单元格示例。细长细胞也被称为镰状细胞
4.2 性能的措施
我们的算法的结果应该使用多个数值和定义良好的度量来测量,以确保质量。这些指标的目的是评估预测凹点位置的精度以及对重叠物体分裂的影响。我们使用了5个指标:MED、F1-Score、SDS_Score、MCC和CBA。
-
欧氏距离(MED)的平均值。设该方法对给定图像检测到的凹点,并为该图像的真凹点,我们知道可能有l≠p。然而,对于GCj存在的每一个点都是最小的,那么我们用(5)定义MED性能度量。
-
F1-Score。它是一种标准的、广泛使用的测量方法。它是精确率和召回率的调和平均值,见(8)。精确率和召回率取决于假阳性(FP)、真阳性(TP)和假阴性(FN)的数量。我们还包括精度和召回的结果,以解释F1-Score。
-
马太相关系数(MCC)[17]中介绍,是预测与观测之间的相关度量。对于多类问题,我们使用Mosley等人[19]提出的自适应方法,见式(9)。该度量在[-1,1]范围内,其中-1表示完全误分类,1表示完全分类,0表示随机分类。它被设计用来处理不平衡的数据。
-
类平衡精度(CBA)。由Mosley等人介绍[19]。它表示从单个类度量的聚合中构建的总体精度度量。这一措施是用来处理不平衡数据的。见(10)。
-
镰状细胞病诊断支持评分(SDS-Score)。Delgado-Font等人[7]提出SDS-Score,表明该方法对镰状细胞病患者的诊断有用。由于疾病的性质,该指标不认为细长细胞和其他细胞之间的错误分类(反之亦然)是错误的。见(11)。
其中cij是类I预测为类j的元素个数,z是类的个数。其中,c23代表被拉长时预测为其他的细胞,c32代表被拉长时预测为其他的细胞。
我们使用配对t检验来检验我们的结果与最先进方法的F1-Score之间的差异。零假设是我们的结果更大。以前,使用Shapiro-Wilk检验来检查数据分布的正态性。
4.3 最先进的方法
在引言中,我们研究了通过寻找凹点来分离重叠对象的最新方法。为了执行我们的实验,我们选择了一个有代表性的子集,排除了由于原始论文中缺乏信息和无法访问源代码而无法复制的方法。
我们使用Zafari等人[30]和González-Hidalgo等人[11]的原始代码。除了上述两种方法外,我们还考虑了以下方法:LaTorre等[16],Fernández等[10],Song和Wang [24], Chaves等[5],Bai等[2],Wang等[26]和Zafari等[32]。
由于我们没有方法的超参数值,为了公平比较,我们进行了穷举搜索,以获得每个实验的每种方法的超参数,见表2,即使我们有它们的原始值。
4.4 实验
我们进行了两个实验来研究所提出方法的两种不同特性。首先是凹点检测的精度。二是检测精度对重叠目标后验分割的影响。
4.4.1 实验1
本实验旨在比较该方法与现有方法的检测能力和空间精度。我们使用生成的OverArt数据集,因为它包含每个凹点的位置。训练集和测试集是通过随机选择1000张图像来构建的,需要注意的是,这两个集之间的交集是空的。
为了评估每种方法的性能,我们使用了4.2节中的两种不同的性能度量:平均欧几里得距离(MED)和F1-Score。为了计算F1-Score,我们将每个检测到的凹点与一个地面真值点相匹配。如果距离小于整数阈值,我们匹配两个点,



